Waarschijnlijkheidstheorie is een speciale tak van de wiskunde die alleen wordt bestudeerd door studenten van instellingen voor hoger onderwijs. Houd jij van berekeningen en formules? Je bent niet bang voor de vooruitzichten om kennis te maken met de normale verdeling, ensemble-entropie, wiskundige verwachtingen en discrete spreiding willekeurige variabele? Dan is dit onderwerp erg interessant voor jou. Laten we een paar van de belangrijkste bekijken basisconcepten deze tak van de wetenschap.
Laten we de basis onthouden
Zelfs als je je het meeste herinnert eenvoudige concepten waarschijnlijkheidstheorie, verwaarloos de eerste paragrafen van het artikel niet. Het punt is dat je zonder een duidelijk begrip van de basisprincipes niet met de hieronder besproken formules kunt werken.
Er vindt dus een willekeurige gebeurtenis plaats, een experiment. Als gevolg van de acties die we ondernemen, kunnen we verschillende resultaten bereiken: sommige komen vaker voor, andere minder vaak. De waarschijnlijkheid van een gebeurtenis is de verhouding tussen het aantal feitelijk verkregen uitkomsten van één type en het totale aantal mogelijke uitkomsten. Alleen maar weten klassieke definitie Met dit concept kun je beginnen met het bestuderen van de wiskundige verwachting en spreiding van continue willekeurige variabelen.
Gemiddeld
Vroeger op school begon je tijdens de wiskundelessen met het rekenkundig gemiddelde te werken. Dit concept wordt veel gebruikt in de waarschijnlijkheidstheorie en kan daarom niet worden genegeerd. Het belangrijkste voor ons is dit moment is dat we het zullen tegenkomen in de formules voor de wiskundige verwachting en spreiding van een willekeurige variabele.

We hebben een reeks getallen en willen het rekenkundig gemiddelde vinden. Het enige dat van ons wordt verlangd, is alles wat beschikbaar is op te sommen en te delen door het aantal elementen in de reeks. Laten we getallen van 1 tot en met 9 hebben. De som van de elementen is gelijk aan 45, en we delen deze waarde door 9. Antwoord: - 5.
Spreiding
Spreken wetenschappelijke taal spreiding is het gemiddelde kwadraat van afwijkingen van de verkregen karakteristieke waarden van het rekenkundig gemiddelde. Het wordt aangegeven met één Latijnse hoofdletter D. Wat is er nodig om het te berekenen? Voor elk element van de reeks berekenen we het verschil tussen het bestaande getal en het rekenkundig gemiddelde en kwadrateren we dit. Er zullen precies zoveel waarden zijn als er uitkomsten kunnen zijn voor de gebeurtenis die we overwegen. Vervolgens vatten we alles wat we hebben ontvangen samen en delen we dit door het aantal elementen in de reeks. Als we vijf mogelijke uitkomsten hebben, deel dan door vijf.

Dispersie heeft ook eigenschappen die onthouden moeten worden om te kunnen gebruiken bij het oplossen van problemen. Wanneer u bijvoorbeeld een willekeurige variabele met X maal vergroot, neemt de variantie toe met X kwadratische maal (d.w.z. X*X). Het is nooit minder dan nul en is niet afhankelijk van het met gelijke hoeveelheden omhoog of omlaag verschuiven van waarden. Bovendien is voor onafhankelijke onderzoeken de variantie van de som gelijk aan de som van de varianties.
Nu moeten we zeker voorbeelden overwegen van de variantie van een discrete willekeurige variabele en de wiskundige verwachting.
Laten we zeggen dat we 21 experimenten hebben uitgevoerd en zeven verschillende uitkomsten hebben gekregen. We hebben ze elk respectievelijk 1, 2, 2, 3, 4, 4 en 5 keer geobserveerd. Waaraan zal de variantie gelijk zijn?
Laten we eerst het rekenkundig gemiddelde berekenen: de som van de elementen is natuurlijk 21. Deel dit door 7 en krijg 3. Trek nu 3 af van elk getal in de oorspronkelijke reeks, kwadraat elke waarde en tel de resultaten bij elkaar op. Het resultaat is 12. Nu hoeven we alleen maar het getal te delen door het aantal elementen, en het lijkt erop dat dat alles is. Maar er zit een addertje onder het gras! Laten we het bespreken.
Afhankelijkheid van het aantal experimenten
Het blijkt dat bij het berekenen van de variantie de noemer twee getallen kan bevatten: N of N-1. Hier is N het aantal uitgevoerde experimenten of het aantal elementen in de reeks (wat in wezen hetzelfde is). Waar hangt dit van af?

Als het aantal tests in honderden wordt gemeten, moeten we N in de noemer plaatsen. Als het in eenheden is, dan is dit N-1. Wetenschappers besloten de grens vrij symbolisch te trekken: vandaag gaat deze door het getal 30. Als we minder dan 30 experimenten hebben uitgevoerd, delen we de hoeveelheid door N-1, en als er meer zijn, dan door N.
Taak
Laten we terugkeren naar ons voorbeeld van het oplossen van het probleem van variantie en wiskundige verwachtingen. We kregen een tussengetal 12, dat gedeeld moest worden door N of N-1. Omdat we 21 experimenten hebben uitgevoerd, wat minder is dan 30, kiezen we voor de tweede optie. Het antwoord is dus: de variantie is 12/2 = 2.
Verwachte waarde
Laten we verder gaan met het tweede concept, dat we in dit artikel moeten overwegen. De wiskundige verwachting is het resultaat van het optellen van alles Mogelijke resultaten, vermenigvuldigd met de overeenkomstige kansen. Het is belangrijk om te begrijpen dat de verkregen waarde, evenals het resultaat van de berekening van de variantie, slechts één keer wordt verkregen de hele taak, ongeacht hoeveel uitkomsten er in aanmerking worden genomen.

De formule voor wiskundige verwachtingen is vrij eenvoudig: we nemen de uitkomst, vermenigvuldigen deze met de waarschijnlijkheid, voegen hetzelfde toe voor het tweede, derde resultaat, enz. Alles wat met dit concept te maken heeft, is niet moeilijk te berekenen. De som van de verwachte waarden is bijvoorbeeld gelijk aan de verwachte waarde van de som. Hetzelfde geldt voor het werk. Niet elke grootheid in de kansrekening stelt je in staat zulke eenvoudige bewerkingen uit te voeren. Laten we het probleem nemen en de betekenis berekenen van twee concepten die we tegelijk hebben bestudeerd. Bovendien werden we afgeleid door de theorie - het is tijd om te oefenen.
Nog een voorbeeld
We hebben 50 onderzoeken uitgevoerd en 10 soorten uitkomsten verkregen – getallen van 0 tot en met 9 – die in verschillende percentages voorkomen. Dit zijn respectievelijk: 2%, 10%, 4%, 14%, 2%,18%, 6%, 16%, 10%, 18%. Bedenk dat u, om kansen te verkrijgen, de procentuele waarden door 100 moet delen. We krijgen dus 0,02; 0,1, enz. Laten we een voorbeeld presenteren van het oplossen van het probleem voor de variantie van een willekeurige variabele en de wiskundige verwachting.
Het rekenkundig gemiddelde berekenen we met de formule die we ons nog herinneren van de basisschool: 50/10 = 5.
Laten we nu de kansen omzetten in het aantal uitkomsten “in stukjes” om het tellen gemakkelijker te maken. We krijgen 1, 5, 2, 7, 1, 9, 3, 8, 5 en 9. Van elke verkregen waarde trekken we het rekenkundig gemiddelde af, waarna we elk van de verkregen resultaten kwadrateren. Bekijk hoe u dit doet met het eerste element als voorbeeld: 1 - 5 = (-4). Volgende: (-4) * (-4) = 16. Voer deze bewerkingen zelf uit voor andere waarden. Als je alles goed hebt gedaan, krijg je na het optellen ervan 90.

Laten we doorgaan met het berekenen van de variantie en de verwachte waarde door 90 te delen door N. Waarom kiezen we N in plaats van N-1? Klopt, want het aantal uitgevoerde experimenten overschrijdt de 30. Dus: 90/10 = 9. We hebben de variantie. Als u een ander nummer krijgt, wanhoop dan niet. Hoogstwaarschijnlijk hebt u een simpele fout gemaakt in de berekeningen. Controleer nogmaals wat je hebt geschreven en alles zal waarschijnlijk op zijn plaats vallen.
Onthoud ten slotte de formule voor wiskundige verwachting. We zullen niet alle berekeningen geven, we zullen alleen een antwoord schrijven dat u kunt controleren nadat u alle vereiste procedures heeft voltooid. De verwachte waarde zal 5,48 zijn. Laten we ons alleen herinneren hoe we bewerkingen moeten uitvoeren, waarbij we de eerste elementen als voorbeeld gebruiken: 0*0,02 + 1*0,1... enzovoort. Zoals u kunt zien, vermenigvuldigen we eenvoudigweg de uitkomstwaarde met de waarschijnlijkheid ervan.
Afwijking
Een ander concept dat nauw verwant is aan spreiding en wiskundige verwachtingen is de standaarddeviatie. Het wordt aangegeven met de Latijnse letters sd, of met de Griekse kleine letter “sigma”. Dit concept laat zien van hoeveel de waarden gemiddeld afwijken centraal kenmerk. Om de waarde ervan te vinden, moet u berekenen Vierkantswortel van verspreiding.

Als u een normale verdelingsgrafiek tekent en deze direct wilt bekijken vierkante afwijking, dit kan in verschillende fasen worden gedaan. Neem de helft van de afbeelding links of rechts van de modus (centrale waarde), teken een loodlijn op de horizontale as zodat de gebieden van de resulterende figuren gelijk zijn. De grootte van het segment tussen het midden van de verdeling en de resulterende projectie op de horizontale as vertegenwoordigt de standaarddeviatie.
Software
Zoals blijkt uit de beschrijvingen van de formules en de gepresenteerde voorbeelden, is het berekenen van variantie en wiskundige verwachtingen vanuit rekenkundig oogpunt niet de eenvoudigste procedure. Om geen tijd te verspillen, is het zinvol om het programma te gebruiken dat in het hoger onderwijs wordt gebruikt onderwijsinstellingen- het heet "R". Het heeft functies waarmee je waarden kunt berekenen voor veel concepten uit de statistiek en de waarschijnlijkheidstheorie.
U specificeert bijvoorbeeld een vector van waarden. Dit gaat als volgt: vector<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
Eindelijk
Zonder deze spreiding en wiskundige verwachting is het moeilijk om iets in de toekomst te berekenen. In het hoofdcollege van de universiteiten worden ze al in de eerste maanden van de studie van het onderwerp besproken. Het is juist vanwege het gebrek aan begrip van deze eenvoudige concepten en het onvermogen om ze te berekenen dat veel studenten onmiddellijk achterop raken in het programma en later slechte cijfers krijgen aan het einde van de sessie, waardoor ze geen studiebeurzen meer krijgen.
Oefen minimaal een week, een half uur per dag, met het oplossen van taken die vergelijkbaar zijn met de taken die in dit artikel worden gepresenteerd. Vervolgens kunt u bij elke test in de waarschijnlijkheidstheorie met de voorbeelden omgaan zonder externe tips en spiekbriefjes.
Variatiebereik (of variatiebereik) - dit is het verschil tussen de maximale en minimale waarden van het kenmerk:
In ons voorbeeld is de variatie in de ploegproductie van werknemers: in de eerste brigade R = 105-95 = 10 kinderen, in de tweede brigade R = 125-75 = 50 kinderen. (5 keer meer). Dit suggereert dat de productie van de 1e brigade ‘stabieler’ is, maar dat de tweede brigade meer reserves heeft om de productie te verhogen, omdat Als alle arbeiders de maximale productie voor deze brigade bereiken, kan deze 3 * 125 = 375 onderdelen produceren, en in de 1e brigade slechts 105 * 3 = 315 onderdelen.
Als de extreme waarden van een kenmerk niet typisch zijn voor de populatie, worden kwartiel- of decielbereiken gebruikt. De kwartielreeks RQ= Q3-Q1 bestrijkt 50% van het bevolkingsvolume, de eerste decielreeks RD1 = D9-D1 bestrijkt 80% van de gegevens, de tweede decielreeks RD2= D8-D2 – 60%.
Het nadeel van de variatiebereikindicator is dat de waarde ervan niet alle fluctuaties van de eigenschap weerspiegelt.
De eenvoudigste algemene indicator die alle fluctuaties van een kenmerk weerspiegelt, is gemiddelde lineaire afwijking, wat het rekenkundig gemiddelde is van de absolute afwijkingen van individuele opties van hun gemiddelde waarde:
,
voor gegroepeerde gegevens ![]() ,
,
waarbij xi de waarde is van het attribuut in een discrete reeks of het midden van het interval in de intervalverdeling.
In de bovenstaande formules worden de verschillen in de teller modulo genomen, anders zal de teller, afhankelijk van de eigenschap van het rekenkundig gemiddelde, altijd gelijk zijn aan nul. Daarom wordt de gemiddelde lineaire afwijking zelden gebruikt in de statistische praktijk, alleen in gevallen waarin het optellen van indicatoren zonder rekening te houden met het teken economisch zinvol is. Met behulp hiervan worden bijvoorbeeld de samenstelling van het personeelsbestand, de winstgevendheid van de productie en de omzet van de buitenlandse handel geanalyseerd.
Variantie van een eigenschap is het gemiddelde kwadraat van afwijkingen van hun gemiddelde waarde:
eenvoudige variantie ![]() ,
,
variantie gewogen  .
.
De formule voor het berekenen van de variantie kan worden vereenvoudigd:
De variantie is dus gelijk aan het verschil tussen het gemiddelde van de vierkanten van de optie en het kwadraat van het gemiddelde van de optie van de populatie:  .
.
Door de optelling van de gekwadrateerde afwijkingen geeft de variantie echter een vertekend beeld van de afwijkingen, dus op basis daarvan wordt het gemiddelde berekend standaardafwijking, die laat zien hoeveel specifieke varianten van een eigenschap gemiddeld afwijken van hun gemiddelde waarde. Berekend door de vierkantswortel van de variantie te nemen:
voor niet-gegroepeerde gegevens  ,
,
voor variatiereeksen 
Hoe kleiner de waarde van de variantie en standaarddeviatie, hoe homogener de populatie, hoe betrouwbaarder (typisch) de gemiddelde waarde zal zijn.
Gemiddelde lineaire en standaardafwijking worden getallen genoemd, dat wil zeggen dat ze worden uitgedrukt in meeteenheden van een kenmerk, identiek zijn qua inhoud en qua betekenis vergelijkbaar zijn.
Het wordt aanbevolen om absolute variaties te berekenen met behulp van tabellen.
Tabel 3 - Berekening van variatiekenmerken (met behulp van het voorbeeld van de periode met gegevens over de ploegendienstoutput van bemanningsleden)
Aantal werknemers |
Het midden van het interval |
Berekende waarden |
|||||
Totaal: |
|||||||
Gemiddelde ploegenproductie van werknemers: ![]()
Gemiddelde lineaire afwijking: ![]()
Productievariantie: 
De standaardafwijking van de productie van individuele werknemers ten opzichte van de gemiddelde productie:
.
1 Berekening van de spreiding met behulp van de momentenmethode
Het berekenen van varianties brengt omslachtige berekeningen met zich mee (vooral als het gemiddelde wordt uitgedrukt als een groot getal met meerdere decimalen). Berekeningen kunnen worden vereenvoudigd door een vereenvoudigde formule en dispersie-eigenschappen te gebruiken.
De dispersie heeft de volgende eigenschappen:
- Als alle waarden van een kenmerk worden verlaagd of verhoogd met dezelfde waarde A, dan neemt de spreiding niet af:
 ,
,
 , dan of
, dan of 
Door gebruik te maken van de eigenschappen van spreiding en eerst alle varianten van de populatie te reduceren met de waarde A, en vervolgens te delen door de waarde van het interval h, verkrijgen we een formule voor het berekenen van de spreiding in variatiereeksen met gelijke intervallen manier van momenten: ,
,
waar wordt de spreiding berekend met behulp van de momentenmethode;
h – de waarde van het interval van de variatiereeks;
– nieuwe (getransformeerde) waardenoptie;
A is een constante waarde, die wordt gebruikt als het midden van het interval met de hoogste frequentie; of de optie met de hoogste frequentie; 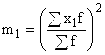 – kwadraat van het eerste-ordemoment;
– kwadraat van het eerste-ordemoment;
– moment van de tweede orde.
Laten we de spreiding berekenen met behulp van de momentenmethode, gebaseerd op gegevens over de ploegenoutput van de werknemers van het team.
Tabel 4 - Variantieberekening met behulp van de momentenmethode
Groepen productiemedewerkers, st. |
Aantal werknemers |
Het midden van het interval |
Berekende waarden |
||
Berekeningsprocedure:


- We berekenen de variantie:
2 Berekening van de variantie van een alternatief kenmerk
Onder de kenmerken die door de statistiek worden bestudeerd, zijn er ook kenmerken die slechts twee elkaar uitsluitende betekenissen hebben. Dit zijn alternatieve tekens. Ze krijgen respectievelijk twee kwantitatieve waarden: optie 1 en 0. De frequentie van optie 1, die wordt aangegeven met p, is het aandeel eenheden dat dit kenmerk bezit. Het verschil 1-р=q is de frequentie van opties 0. Dus
xi |
|
Rekenkundig gemiddelde van het alternatieve teken ![]() , omdat p+q=1.
, omdat p+q=1.
Alternatieve eigenschapsvariantie
, omdat 1-ð=q
De variantie van een alternatief kenmerk is dus gelijk aan het product van het aandeel eenheden dat dit kenmerk bezit en het aandeel eenheden dat dit kenmerk niet bezit.
Als de waarden 1 en 0 even vaak voorkomen, dat wil zeggen p=q, bereikt de variantie zijn maximale pq=0,25.
De variantie van een alternatief attribuut wordt gebruikt in steekproefonderzoeken, bijvoorbeeld naar productkwaliteit.
3 Variantie tussen groepen. Variantietoevoegingsregel
Dispersie is, in tegenstelling tot andere kenmerken van variatie, een additieve hoeveelheid. Dat wil zeggen, in totaal, verdeeld in groepen op basis van factorkenmerken X , variantie van het resulterende kenmerk j kan worden ontleed in de variantie binnen elke groep (binnen groepen) en de variantie tussen groepen (tussen groepen). Vervolgens wordt het, naast het bestuderen van de variatie van een eigenschap binnen de gehele populatie als geheel, mogelijk om de variatie in elke groep, maar ook tussen deze groepen, te bestuderen.
Totale variantie meet de variatie in een eigenschap bij in zijn geheel onder invloed van alle factoren die deze variatie (afwijkingen) veroorzaakten. Het is gelijk aan de gemiddelde vierkante afwijking van individuele waarden van het attribuut bij van het eindgemiddelde en kan worden berekend als eenvoudige of gewogen variantie.
Variantie tussen groepen karakteriseert de variatie van de resulterende eigenschap bij veroorzaakt door de invloed van het factorteken X, die de basis vormden van de groepering. Het karakteriseert de variatie van groepsgemiddelden en is gelijk aan het gemiddelde kwadraat van de afwijkingen van groepsgemiddelden ten opzichte van het algemene gemiddelde:  ,
,
waar is het rekenkundig gemiddelde van de i-de groep;
– aantal eenheden in de i-de groep (frequentie van de i-de groep);
– het algemene gemiddelde van de bevolking.
Variantie binnen de groep weerspiegelt willekeurige variatie, d.w.z. dat deel van de variatie dat wordt veroorzaakt door de invloed van niet-verantwoorde factoren en niet afhankelijk is van het factorattribuut dat de basis vormt van de groepering. Het karakteriseert de variatie van individuele waarden ten opzichte van groepsgemiddelden en is gelijk aan de gemiddelde kwadratische afwijking van individuele waarden van het attribuut bij binnen een groep uit het rekenkundig gemiddelde van deze groep (groepsgemiddelde) en wordt voor elke groep berekend als een eenvoudige of gewogen variantie: ![]() of
of ![]() ,
,
waar is het aantal eenheden in de groep.
Op basis van de varianties binnen de groep voor elke groep kan men bepalen algemeen gemiddelde van varianties binnen de groep:
.
De relatie tussen de drie dispersies wordt genoemd regels voor het optellen van varianties, volgens welke de totale variantie gelijk is aan de som van de variantie tussen groepen en het gemiddelde van de varianties binnen de groep:
Voorbeeld. Bij het bestuderen van de invloed van de tariefcategorie (kwalificatie) van werknemers op het productiviteitsniveau van hun arbeid werden de volgende gegevens verkregen.
Tabel 5 – Verdeling van werknemers naar gemiddelde uurproductie.
№ p/p |
Arbeiders van de 4e categorie |
Arbeiders van de 5e categorie |
|||||
Uitvoer |
Uitvoer |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
In dit voorbeeld worden werknemers op basis van factorkenmerken in twee groepen verdeeld X– kwalificaties, die worden gekenmerkt door hun rang. De resulterende eigenschap – productie – varieert zowel onder de invloed ervan (intergroepsvariatie) als als gevolg van andere willekeurige factoren (intragroepsvariatie). Het doel is om deze variaties te meten met behulp van drie varianten: totaal, tussen groepen en binnen groepen. De empirische determinatiecoëfficiënt toont het aandeel van de variatie in het resulterende kenmerk bij onder invloed van een factorteken X. Rest van de totale variatie bij veroorzaakt door veranderingen in andere factoren.
In het voorbeeld is de empirische determinatiecoëfficiënt: ![]() of 66,7%,
of 66,7%,
Dit betekent dat 66,7% van de variatie in de productiviteit van werknemers te wijten is aan verschillen in kwalificaties, en 33,3% aan de invloed van andere factoren.
Empirische correlatierelatie toont het nauwe verband tussen groepering en prestatiekenmerken. Berekend als de vierkantswortel van de empirische determinatiecoëfficiënt:
De empirische correlatieverhouding, zoals , kan waarden aannemen van 0 tot 1.
Als er geen verbinding is, dan =0. In dit geval =0, dat wil zeggen dat de groepsgemiddelden aan elkaar gelijk zijn en dat er geen intergroepsvariatie is. Dit betekent dat de groeperingskenmerkfactor geen invloed heeft op de vorming van algemene variatie.
Als de verbinding functioneel is, dan =1. In dit geval is de variantie van het groepsgemiddelde gelijk aan de totale variantie (), dat wil zeggen dat er geen variatie binnen de groep is. Dit betekent dat het groeperingskenmerk volledig de variatie bepaalt van het resulterende kenmerk dat wordt bestudeerd.
Hoe dichter de waarde van de correlatieverhouding bij de eenheid ligt, hoe dichter, dichter bij de functionele afhankelijkheid, het verband tussen de kenmerken is.
Om de nauwe samenhang tussen kenmerken kwalitatief te beoordelen, worden de relaties van Chaddock gebruikt.
In het voorbeeld ![]() , wat wijst op een nauw verband tussen de productiviteit van werknemers en hun kwalificaties.
, wat wijst op een nauw verband tussen de productiviteit van werknemers en hun kwalificaties.
Variantie is een spreidingsmaatstaf die de vergelijkende afwijking tussen gegevenswaarden en het gemiddelde beschrijft. Het is de meest gebruikte maatstaf voor spreiding in statistieken, berekend door de afwijking van elke gegevenswaarde ten opzichte van het gemiddelde op te tellen en te kwadrateren. De formule voor het berekenen van de variantie wordt hieronder gegeven:
![]()
s 2 – steekproefvariantie;
x av: steekproefgemiddelde;
N — steekproefomvang (aantal gegevenswaarden),
(x i – x avg) is de afwijking van de gemiddelde waarde voor elke waarde van de gegevensset.
Laten we een voorbeeld bekijken om de formule beter te begrijpen. Ik hou niet zo van koken, dus ik doe het zelden. Om echter niet te verhongeren, moet ik van tijd tot tijd naar de kachel gaan om het plan uit te voeren om mijn lichaam te verzadigen met eiwitten, vetten en koolhydraten. De onderstaande dataset laat zien hoe vaak Renat elke maand kookt:
De eerste stap bij het berekenen van de variantie is het bepalen van het steekproefgemiddelde, dat in ons voorbeeld 7,8 keer per maand is. De rest van de berekeningen kunnen eenvoudiger worden gemaakt met behulp van de volgende tabel.

De laatste fase van het berekenen van de variantie ziet er als volgt uit:
![]()
Voor degenen die alle berekeningen in één keer willen uitvoeren, zou de vergelijking er als volgt uitzien:
Gebruik van de rauwe telmethode (kookvoorbeeld)
Er is een efficiëntere manier om de variantie te berekenen, de zogenaamde raw count-methode. Hoewel de vergelijking op het eerste gezicht nogal omslachtig lijkt, is deze in werkelijkheid niet zo eng. U kunt hier zeker van zijn en vervolgens beslissen welke methode u het beste bevalt.

is de som van elke gegevenswaarde na kwadrateren,
is het kwadraat van de som van alle gegevenswaarden.
Verlies je verstand nu niet. Laten we dit allemaal in een tabel zetten en je zult zien dat er minder berekeningen nodig zijn dan in het vorige voorbeeld.


Zoals u kunt zien, was het resultaat hetzelfde als bij gebruik van de vorige methode. De voordelen van deze methode worden duidelijk naarmate de steekproefomvang (n) toeneemt.
Variantieberekening in Excel
Zoals u waarschijnlijk al geraden heeft, heeft Excel een formule waarmee u de variantie kunt berekenen. Bovendien kunt u vanaf Excel 2010 4 soorten variantieformules vinden:
1) VARIANCE.V – Geeft de variantie van de steekproef terug. Booleaanse waarden en tekst worden genegeerd.
2) DISP.G - Geeft de variantie van de populatie terug. Booleaanse waarden en tekst worden genegeerd.
3) VARIANCE - Geeft de variantie van de steekproef terug, rekening houdend met Booleaanse waarden en tekstwaarden.
4) VARIANTIE - Geeft de variantie van de populatie terug, rekening houdend met logische waarden en tekstwaarden.
Laten we eerst het verschil begrijpen tussen een steekproef en een populatie. Het doel van beschrijvende statistieken is om gegevens samen te vatten of weer te geven, zodat u snel het grote geheel krijgt, een overzicht om zo te zeggen. Met statistische gevolgtrekkingen kunt u conclusies trekken over een populatie op basis van een steekproef van gegevens uit die populatie. De populatie vertegenwoordigt alle mogelijke uitkomsten of metingen die voor ons van belang zijn. Een steekproef is een subset van een populatie.
We zijn bijvoorbeeld geïnteresseerd in een groep studenten van een van de Russische universiteiten en we moeten de gemiddelde score van de groep bepalen. We kunnen de gemiddelde prestaties van studenten berekenen, en dan zal het resulterende cijfer een parameter zijn, aangezien de hele bevolking bij onze berekeningen betrokken zal zijn. Als we echter de GPA van alle studenten in ons land willen berekenen, dan zal deze groep onze steekproef zijn.
Het verschil in de formule voor het berekenen van de variantie tussen een steekproef en een populatie is de noemer. Waarbij het voor de steekproef gelijk zal zijn aan (n-1), en voor de algemene bevolking alleen n.
Laten we nu eens kijken naar de functies voor het berekenen van variantie met eindes A, waarvan de beschrijving vermeldt dat bij de berekening rekening wordt gehouden met tekst en logische waarden. In dit geval zal Excel bij het berekenen van de variantie van een bepaalde dataset waarin niet-numerieke waarden voorkomen, tekst en valse Booleaanse waarden interpreteren als gelijk aan 0, en echte Booleaanse waarden als gelijk aan 1.
Dus als u een gegevensarray heeft, zal het berekenen van de variantie ervan niet moeilijk zijn met behulp van een van de hierboven genoemde Excel-functies.

Dispersie in statistieken wordt gedefinieerd als de standaardafwijking van individuele waarden van een kenmerk in het kwadraat van het rekenkundig gemiddelde. Een veelgebruikte methode om de kwadratische afwijkingen van opties van het gemiddelde te berekenen en deze vervolgens te middelen.
![]()
Bij economische statistische analyses is het gebruikelijk om de variatie van een kenmerk te evalueren, meestal met behulp van de standaardafwijking; dit is de vierkantswortel van de variantie.
 (3)
(3)
Karakteriseert de absolute fluctuatie van de waarden van een variërend kenmerk en wordt uitgedrukt in dezelfde meeteenheden als de opties. In de statistiek is het vaak nodig om de variatie van verschillende kenmerken te vergelijken. Voor dergelijke vergelijkingen wordt een relatieve variatiemaatstaf, de variatiecoëfficiënt, gebruikt.
Dispersie-eigenschappen:
1) als u een getal van alle opties aftrekt, verandert de variantie niet;
2) als alle waarden van de optie worden gedeeld door een getal b, dan neemt de variantie af met b^2 keer, d.w.z.
3) als je het gemiddelde kwadraat van de afwijkingen berekent van een getal met een ongelijk rekenkundig gemiddelde, dan zal dit groter zijn dan de variantie. Tegelijkertijd wordt door een goed gedefinieerde waarde per vierkant het verschil tussen de gemiddelde waarde c.
![]()
Dispersie kan worden gedefinieerd als het verschil tussen het kwadraat van het gemiddelde en het kwadraat van het gemiddelde.
17. Groeps- en intergroepsvariaties. Variantietoevoegingsregel
Als een statistische populatie wordt opgedeeld in groepen of delen op basis van het kenmerk dat wordt bestudeerd, kunnen voor een dergelijke populatie de volgende soorten spreiding worden berekend: groep (privé), groepsgemiddelde (privé) en intergroep.
Totale variantie– weerspiegelt de variatie van een kenmerk als gevolg van alle omstandigheden en oorzaken die in een bepaalde statistische populatie voorkomen. ![]()
Groepsvariantie- gelijk aan het gemiddelde kwadraat van afwijkingen van individuele waarden van een kenmerk binnen een groep van het rekenkundig gemiddelde van deze groep, het groepsgemiddelde genoemd. Het groepsgemiddelde komt echter niet overeen met het totaalgemiddelde voor de gehele bevolking.
![]()
Groepsvariantie weerspiegelt de variatie van een eigenschap alleen als gevolg van omstandigheden en oorzaken die binnen de groep werkzaam zijn.
Gemiddelde van groepsvarianties- wordt gedefinieerd als het gewogen rekenkundige gemiddelde van de groepsvarianties, waarbij de gewichten de groepsvolumes zijn.
Variantie tussen groepen- gelijk aan het gemiddelde kwadraat van de afwijkingen van de groepsgemiddelden van het algemene gemiddelde.
Intergroepsspreiding karakteriseert de variatie van het effectieve kenmerk als gevolg van het groeperingskenmerk.
Er bestaat een zekere relatie tussen de soorten spreidingen die in beschouwing worden genomen: de totale spreiding is gelijk aan de som van de gemiddelde groeps- en intergroepsspreiding.
Deze relatie wordt de variantie-optelregel genoemd.
18. Dynamische series en zijn componenten. Soorten tijdreeksen.
Rij in statistieken- dit zijn digitale gegevens die de verandering van een fenomeen in tijd of ruimte laten zien en het mogelijk maken een statistische vergelijking te maken van verschijnselen, zowel in het proces van hun ontwikkeling in de tijd als in verschillende vormen en soorten processen. Dankzij dit is het mogelijk om de wederzijdse afhankelijkheid van verschijnselen te detecteren.
In de statistiek wordt het proces van ontwikkeling van de beweging van sociale verschijnselen in de loop van de tijd gewoonlijk dynamiek genoemd. Om de dynamiek weer te geven, worden dynamische reeksen (chronologisch, tijd) geconstrueerd, dit zijn reeksen van in de tijd variërende waarden van een statistische indicator (bijvoorbeeld het aantal veroordeelde mensen over een periode van 10 jaar), gerangschikt in chronologische volgorde. Hun samenstellende elementen zijn de digitale waarden van een bepaalde indicator en de perioden of tijdstippen waarop ze betrekking hebben.
Het belangrijkste kenmerk van dynamische series- hun omvang (volume, magnitude) van een bepaald fenomeen dat in een bepaalde periode of op een bepaald moment wordt bereikt. Dienovereenkomstig is de omvang van de termen van de dynamiekreeks het niveau ervan. Onderscheiden begin-, midden- en eindniveau van de dynamische reeks. Eerste level toont de waarde van de eerste, de laatste - de waarde van de laatste term van de reeks. Gemiddeld niveau vertegenwoordigt het gemiddelde chronologische variatiebereik en wordt berekend afhankelijk van het feit of de dynamische reeks interval- of kortstondig is.
Een ander belangrijk kenmerk van de dynamische serie- de tijd die is verstreken tussen de eerste en de laatste waarneming, of het aantal van dergelijke waarnemingen.
Er zijn verschillende soorten tijdreeksen; deze kunnen worden geclassificeerd op basis van de volgende criteria.
1) Afhankelijk van de manier waarop de niveaus worden uitgedrukt, worden de dynamiekreeksen onderverdeeld in reeksen van absolute en afgeleide indicatoren (relatieve en gemiddelde waarden).
2) Afhankelijk van hoe de niveaus van de reeks de toestand van het fenomeen op bepaalde tijdstippen (aan het begin van de maand, het kwartaal, het jaar, enz.) uitdrukken of de waarde ervan over bepaalde tijdsintervallen (bijvoorbeeld per dag, maand, jaar, enz.) enz.), maak onderscheid tussen respectievelijk moment- en intervaldynamiekreeksen. Momentreeksen worden relatief zelden gebruikt in het analytische werk van wetshandhavingsinstanties.
In de statistische theorie wordt de dynamiek onderscheiden volgens een aantal andere classificatiecriteria: afhankelijk van de afstand tussen niveaus - met gelijke niveaus en ongelijke niveaus in de tijd; afhankelijk van de aanwezigheid van de hoofdtendens van het proces dat wordt bestudeerd - stationair en niet-stationair. Bij het analyseren van tijdreeksen gaan ze uit van het volgende; de niveaus van de reeks worden gepresenteerd in de vorm van componenten:
Yt = TP + E (t)
waarbij TP een deterministische component is die de algemene tendens van verandering in de loop van de tijd of trend bepaalt.
E (t) is een willekeurige component die schommelingen in de niveaus veroorzaakt.
Deze pagina beschrijft een standaardvoorbeeld van het vinden van variantie. U kunt ook naar andere problemen kijken om deze te vinden
Voorbeeld 1. Bepaling van groeps-, groepsgemiddelde, intergroeps- en totale variantie
Voorbeeld 2. Het vinden van de variantie en de variatiecoëfficiënt in een groeperingstabel
Voorbeeld 3. Variantie vinden in een discrete reeks
Voorbeeld 4. De volgende gegevens zijn beschikbaar voor een groep van 20 correspondentiestudenten. Het is noodzakelijk om een intervalreeks van de verdeling van het kenmerk te construeren, de gemiddelde waarde van het kenmerk te berekenen en de spreiding ervan te bestuderen
Laten we een intervalgroepering maken. Laten we het bereik van het interval bepalen met behulp van de formule:
![]()
waarbij X max de maximale waarde van het groeperingskenmerk is;
X min – minimumwaarde van het groeperingskenmerk;
n – aantal intervallen:
Wij accepteren n=5. De stap is: h = (192 - 159)/ 5 = 6,6
Laten we een intervalgroepering maken

Voor verdere berekeningen zullen we een hulptabel bouwen:

X"i – het midden van het interval. (bijvoorbeeld het midden van het interval 159 – 165,6 = 162,3)
We bepalen de gemiddelde lengte van studenten met behulp van de gewogen rekenkundig gemiddelde formule:

Laten we de variantie bepalen met behulp van de formule:
De formule kan als volgt worden getransformeerd:

Uit deze formule volgt dat variantie is gelijk aan het verschil tussen het gemiddelde van de vierkanten van de opties en het vierkant en het gemiddelde.
Verspreiding in variatiereeksen met gelijke intervallen met behulp van de momentenmethode kan op de volgende manier worden berekend met behulp van de tweede eigenschap van spreiding (alle opties delen door de waarde van het interval). Variantie bepalen, berekend met behulp van de momentenmethode, is het gebruik van de volgende formule minder bewerkelijk:

waarbij i de waarde van het interval is;
A is een conventionele nul, waarvoor het handig is om het midden van het interval met de hoogste frequentie te gebruiken;
m1 is het kwadraat van het moment van de eerste orde;
m2 - moment van tweede orde
Alternatieve eigenschapsvariantie (als in een statistische populatie een kenmerk zodanig verandert dat er slechts twee elkaar uitsluitende opties zijn, dan wordt een dergelijke variabiliteit alternatief genoemd) kan worden berekend met behulp van de formule:

Als we q = 1-p in deze dispersieformule vervangen, krijgen we:

Soorten variantie
Totale variantie meet de variatie van een kenmerk over de gehele populatie als geheel onder invloed van alle factoren die deze variatie veroorzaken. Het is gelijk aan het gemiddelde kwadraat van de afwijkingen van individuele waarden van een kenmerk x van de totale gemiddelde waarde van x en kan worden gedefinieerd als eenvoudige variantie of gewogen variantie.
Variantie binnen de groep karakteriseert willekeurige variatie, d.w.z. een deel van de variatie dat te wijten is aan de invloed van niet-verantwoorde factoren en niet afhankelijk is van het factorattribuut dat de basis van de groep vormt. Een dergelijke spreiding is gelijk aan het gemiddelde kwadraat van de afwijkingen van individuele waarden van het attribuut binnen groep X van het rekenkundig gemiddelde van de groep en kan worden berekend als eenvoudige spreiding of als gewogen spreiding.
Dus, maatstaven voor variantie binnen de groep variatie van een eigenschap binnen een groep en wordt bepaald door de formule:

waarbij xi het groepsgemiddelde is;
ni is het aantal eenheden in de groep.
Variaties binnen groepen die moeten worden bepaald bij het bestuderen van de invloed van de kwalificaties van werknemers op het niveau van de arbeidsproductiviteit in een werkplaats, laten bijvoorbeeld variaties in de productie in elke groep zien, veroorzaakt door alle mogelijke factoren (technische toestand van de apparatuur, beschikbaarheid van gereedschappen en materialen, leeftijd van de werknemers, arbeidsintensiteit, enz.), behalve verschillen in kwalificatiecategorie (binnen een groep hebben alle werknemers dezelfde kwalificaties).